[('female',
sex age
1 female 38.0
2 female 26.0
3 female 35.0
8 female 27.0
9 female 14.0),
('male',
sex age
0 male 22.0
4 male 35.0
5 male NaN
6 male 54.0
7 male 2.0)]
len(l)
2
l[0]
('female',
sex age
1 female 38.0
2 female 26.0
3 female 35.0
8 female 27.0
9 female 14.0)
type(l[0])
tuple
l[0][0]
'female'
l[0][1]
sex
age
1
female
38.0
2
female
26.0
3
female
35.0
8
female
27.0
9
female
14.0
type(l[0][1])
pandas.core.frame.DataFrame
l[1]
('male',
sex age
0 male 22.0
4 male 35.0
5 male NaN
6 male 54.0
7 male 2.0)
[('AFG',
Year City Sport Discipline Athlete Country Gender \
28965 2008 Beijing Taekwondo Taekwondo NIKPAI, Rohullah AFG Men
30929 2012 London Taekwondo Taekwondo NIKPAI, Rohullah AFG Men
Event Medal
28965 - 58 KG Bronze
30929 58 - 68 KG Bronze ),
('AHO',
Year City Sport Discipline Athlete Country Gender \
19323 1988 Seoul Sailing Sailing BOERSMA, Jan D. AHO Men
Event Medal
19323 Board (Division Ii) Silver )]
len(l)
147
l[100][1]
Year
City
Sport
Discipline
Athlete
Country
Gender
Event
Medal
5031
1928
Amsterdam
Aquatics
Swimming
YLDEFONSO, Teofilo
PHI
Men
200M Breaststroke
Bronze
5741
1932
Los Angeles
Aquatics
Swimming
YLDEFONSO, Teofilo
PHI
Men
200M Breaststroke
Bronze
5889
1932
Los Angeles
Athletics
Athletics
TORIBIO, Simeon Galvez
PHI
Men
High Jump
Bronze
5922
1932
Los Angeles
Boxing
Boxing
VILLANUEVA, Jose
PHI
Men
50.8 - 54KG (Bantamweight)
Bronze
6447
1936
Berlin
Athletics
Athletics
WHITE, Miguel S.
PHI
Men
400M Hurdles
Bronze
11005
1964
Tokyo
Boxing
Boxing
VILLANUEVA, Anthony N.
PHI
Men
54 - 57KG (Featherweight)
Silver
18513
1988
Seoul
Boxing
Boxing
SERANTES, Leopoldo
PHI
Men
- 48KG (Light-Flyweight)
Bronze
20184
1992
Barcelona
Boxing
Boxing
VELASCO, Roel
PHI
Men
- 48KG (Light-Flyweight)
Bronze
21927
1996
Atlanta
Boxing
Boxing
VELASCO, Mansueto
PHI
Men
- 48KG (Light-Flyweight)
Silver
split2=summer.groupby(by=["Country","Gender"])
l2=list(split2)l2[:2]
[(('AFG', 'Men'),
Year City Sport Discipline Athlete Country Gender \
28965 2008 Beijing Taekwondo Taekwondo NIKPAI, Rohullah AFG Men
30929 2012 London Taekwondo Taekwondo NIKPAI, Rohullah AFG Men
Event Medal
28965 - 58 KG Bronze
30929 58 - 68 KG Bronze ),
(('AHO', 'Men'),
Year City Sport Discipline Athlete Country Gender \
19323 1988 Seoul Sailing Sailing BOERSMA, Jan D. AHO Men
Event Medal
19323 Board (Division Ii) Silver )]
len(l2)
236
l2[104]
l2[104][0]
l2[104][1]
split-apply-combine explained
importpandasaspd
titanic=pd.read_csv("titanic.csv")
titanic_slice=titanic.iloc[:10,[2,3]]
titanic_slice
sex
age
0
male
22.0
1
female
38.0
2
female
26.0
3
female
35.0
4
male
35.0
5
male
NaN
6
male
54.0
7
male
2.0
8
female
27.0
9
female
14.0
list(titanic_slice.groupby("sex"))[0][1]
sex
age
1
female
38.0
2
female
26.0
3
female
35.0
8
female
27.0
9
female
14.0
list(titanic_slice.groupby("sex"))[1][1]
titanic_slice.groupby("sex").mean()
age
sex
female
28.00
male
28.25
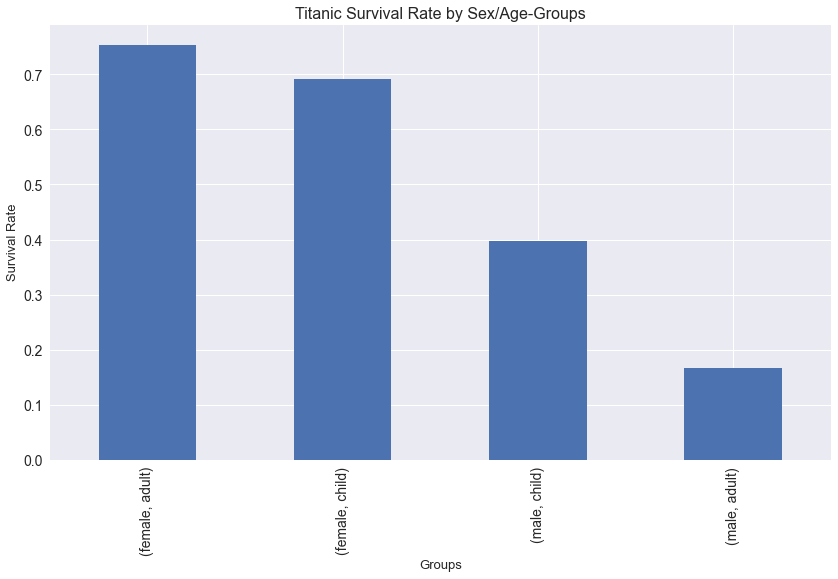
titanic.groupby("sex").survived.sum()
sex
female 233
male 109
Name: survived, dtype: int64
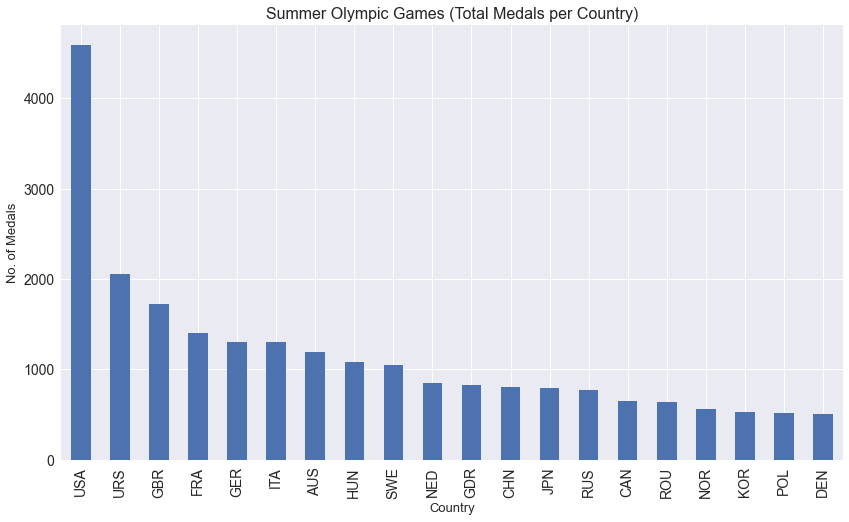
Country
USA 4585
URS 2049
GBR 1720
FRA 1396
GER 1305
ITA 1296
AUS 1189
HUN 1079
SWE 1044
NED 851
GDR 825
CHN 807
JPN 788
RUS 768
CAN 649
ROU 640
NOR 554
KOR 529
POL 511
DEN 507
Name: Medal, dtype: int64
medals_per_country.plot(kind="bar",figsize=(14,8),fontsize=14)plt.xlabel("Country",fontsize=13)plt.ylabel("No. of Medals",fontsize=13)plt.title("Summer Olympic Games (Total Medals per Country)",fontsize=16)plt.show()
C:\Users\LENOVO\AppData\Local\Temp/ipykernel_19564/2434558135.py:1: FutureWarning: Dropping of nuisance columns in DataFrame reductions (with 'numeric_only=None') is deprecated; in a future version this will raise TypeError. Select only valid columns before calling the reduction.
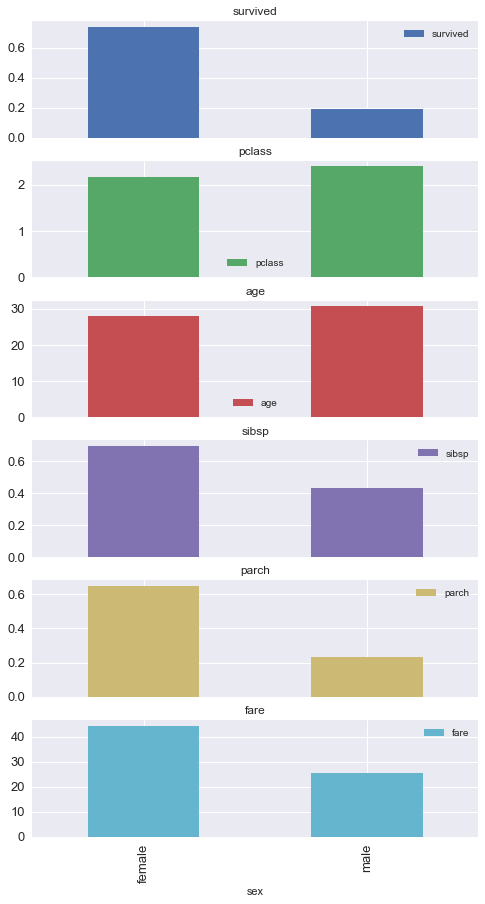
female_group.mean().astype("float")
survived 0.742038
pclass 2.159236
age 27.915709
fare 44.479818
dtype: float64
defgroup_mean(group):returngroup.mean()
group_mean(female_group)
C:\Users\LENOVO\AppData\Local\Temp/ipykernel_19564/359042690.py:2: FutureWarning: Dropping of nuisance columns in DataFrame reductions (with 'numeric_only=None') is deprecated; in a future version this will raise TypeError. Select only valid columns before calling the reduction.
return group.mean()
survived 0.742038
pclass 2.159236
age 27.915709
fare 44.479818
dtype: float64
titanic.groupby("sex").apply(group_mean)
C:\Users\LENOVO\AppData\Local\Temp/ipykernel_19564/359042690.py:2: FutureWarning: Dropping of nuisance columns in DataFrame reductions (with 'numeric_only=None') is deprecated; in a future version this will raise TypeError. Select only valid columns before calling the reduction.
return group.mean()
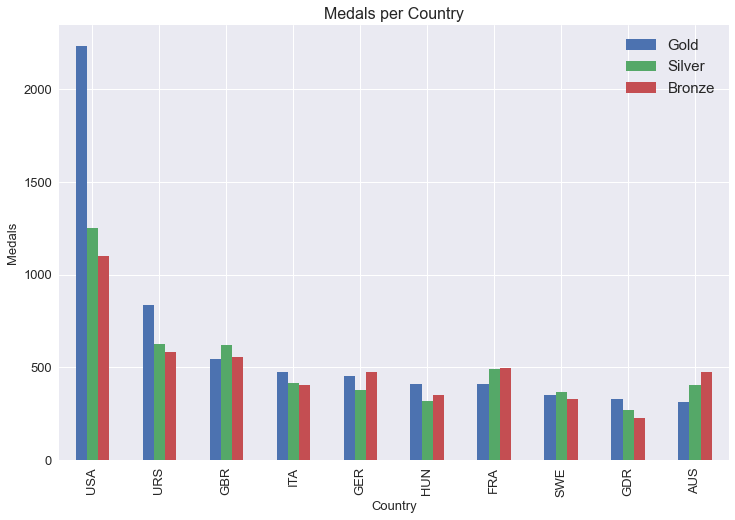
medals_by_country.head(10).plot(kind="bar",figsize=(12,8),fontsize=13)plt.xlabel("Country",fontsize=13)plt.ylabel("Medals",fontsize=13)plt.title("Medals per Country",fontsize=16)plt.legend(fontsize=15)plt.show()
medals_by_country.stack().unstack()
Country Medal
USA Gold 2235
Silver 1252
Bronze 1098
URS Gold 838
Silver 627
...
NIG Silver 0
Bronze 1
TOG Gold 0
Silver 0
Bronze 1
Length: 441, dtype: int64