Interval Estimation
In statistics, interval estimation is the use of sample data to estimate an interval of plausible values of a parameter of interest.
We hold study with 200 participates. This study shows that men on average over 15.7 hours reading books. If the error range for this study is 2.2 hours. Calculate the confidence interval with a certainty level 95%.
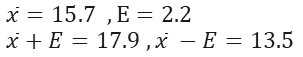
Now we can say with 95% confidence that the average of this sample is between 13.5 and 17.9.
Inferential statistics:
Inferential statistics is a set of methods in which the characteristics of society are inferred with the help of samples.
The main difference between descriptive and inferential statistics is that in descriptive statistics, the results obtained from the statistical sample can never be generalized to the entire statistical population.
Because the goal in this type of statistics is to provide a description of the characteristics of the statistical sample of the research along with There are indicators of tendency towards the center or indicators of tendency towards dispersion.
While in inferential or analytical statistics, the results and findings obtained from the statistical sample can be generalized to the entire statistical population of the research.
Statistical hypothesis testing
In the science of statistics, it is a method to investigate claims or assumptions about distribution parameters in statistical societies. In this method, we are trying to examine the issue and test two hypotheses by using the two concepts of null hypothesis and opposite or alternative hypothesis.
Example: A company claims that the average life of the lamps produced by this company is at least 8000 hours.
Example: A pharmaceutical company claims that their drug for cancer has significantly prevented the spread of cancer, and 80% of users have not had a particular cancer develop in them.
Null Hypothesis \((H_0)\)
Current values we accept for parameters.
Alternative Hypothesis (\(𝑯_𝒂\) , \(𝑯_𝟏\))
Sometimes it is also called a research hypothesis and it includes a claim that we want to investigate.
Test Statistic
The amount obtained from the sample and based on it we make a decision regarding the claim.
Level of Confidence
How confident are we in our decisions?
Based on that, another level is also defined, which is called a meaningful level.
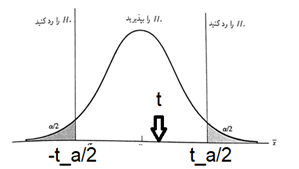
two-tailed (two-sided) tests
Consider a situation where we want to test the null hypothesis \(𝐻_0\): \(\theta\) = \(\theta_0\) against the opposite (alternative) two-sided hypothesis \(𝐻_1\): \(\theta\) \(\neq\) \(\theta_0\) (\(\theta\)> \(\theta_0\), \(\theta\)< \(\theta_0\)).
It seems reasonable to accept the null hypothesis when the point estimate \(\hat \theta\) for the parameter \(\theta\) is close to \(\theta_0\) and to reject it when \(\hat \theta\) is much larger or smaller than \(\theta_0\).
We call tests with the above situation two-tailed (two-sided) tests.
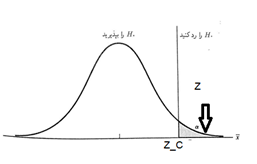
one-tailed (one-sided) tests
Consider a situation where we want to test the null hypothesis \(𝐻_0\): \(\theta\) \(\leq\) \(\theta_0\) against the opposite (alternative) one-sided hypothesis \(𝐻_1\): \(\theta\)>\(\theta_0\).
It seems reasonable to reject the null hypothesis when the point estimate 𝜃̂ for the parameter \(\theta\) is much larger than \(\theta_0\).
We call tests with the above situation one-tailed (one-sided) tests.
Some examples for a better understanding of null hypothesis and counter hypothesis (alternative):
Example 1) A company claims that the coffee machine of this company pours 250 ml of coffee in coffee cups on average. A buyer claims that after repairing the coffee machine of this company, this coffee machine no longer pours an average of 250 ml of coffee. It is desirable to write null hypothesis and alternative hypothesis.
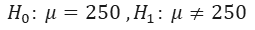
Example 2) Doctors believe that teenagers do not sleep more than 10 hours a day on average. A researcher believes that teenagers sleep more than 10 hours a day. It is desirable to write null hypothesis and alternative hypothesis.
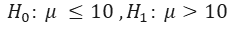
Steps of an assumption test:
1- Formulating the null hypothesis \(𝐻_0\) and the reciprocal hypothesis \(𝐻_1\) and determining \(\alpha\)
2- Determine the critical region \(\alpha\) by using the sampling distribution, the appropriate test statistic.
3- Determine the value of the test statistic from the sample data.
4- Check whether the value of the test statistic falls in the critical area or not and reject or confirm the null hypothesis accordingly.
Example 1) Doctors believe that teenagers do not sleep more than 10 hours a day on average. A researcher believes that teenagers sleep more than 10 hours a day. It is desirable to check this claim with a hypothesis test. The researcher has studied a number of samples, for example 20 teenagers.
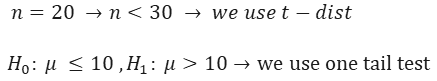
Example 1) A device pours an average of 2 liters of soda into the glasses. After repairing this machine, the management thinks that the machine is not working properly. If the average of a sample of 20 is equal to 2.10 liters and the standard deviation is equal to 0.33, it is desirable to investigate the claim with a significance level of \(\alpha\)=𝟎.𝟎𝟏
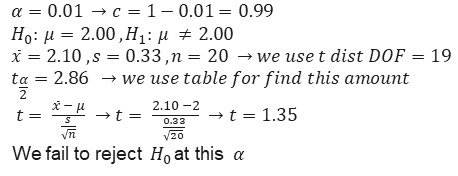
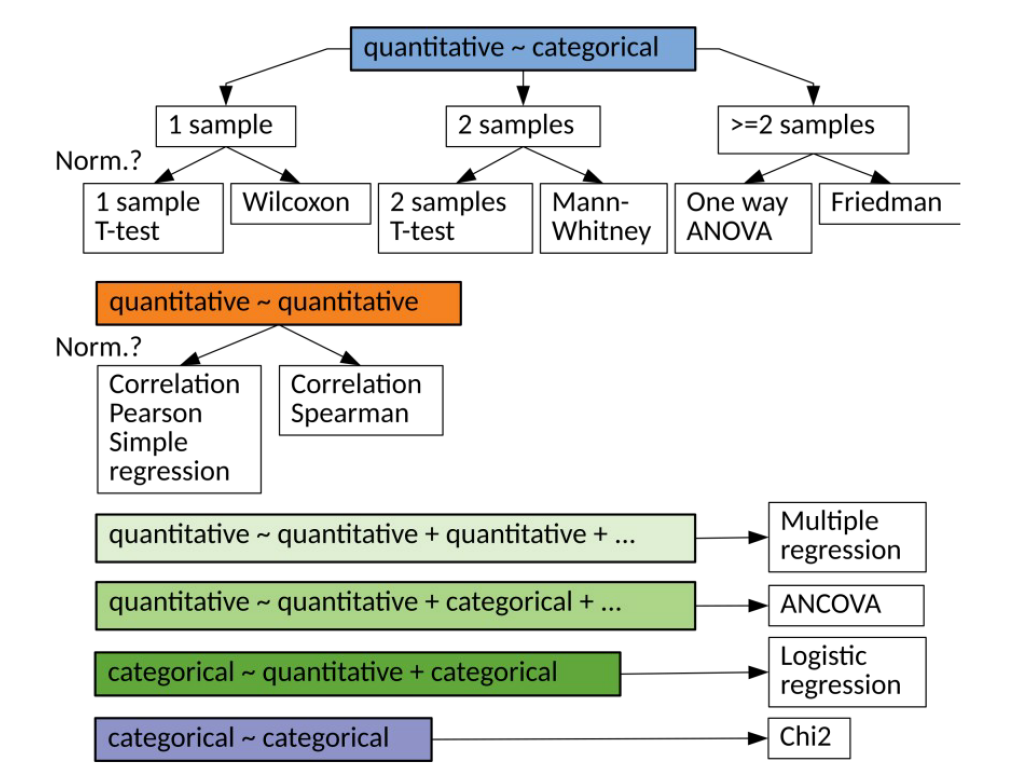
Examples for testing the assumption of the mean of a population (large sample z-test)
Example 1) The results show that the average score of students in a test is less than 850. A company claims that the students who have attended the courses of this company have received a higher average grade. If we have a sample of 1000 with an average of 856 and a standard deviation of 98, it is desirable to check this claim with a significance level of 0.05.
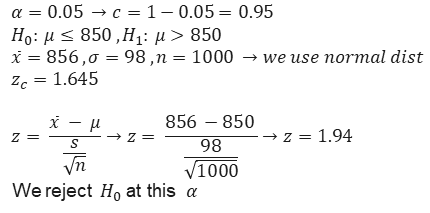
P-value
The lowest value of the probability of type 1 error (test level) that can be found in the test statistic will cause the null hypothesis to be rejected. In other words, in a hypothesis test, the probability value (p-value) is equal to the lowest value of the significance level (significance level) or the probability of the first type error, which causes the null hypothesis to be rejected.
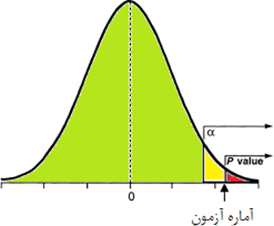

Examples for deciding with 𝒑-𝒗𝒂𝒍𝒖𝒆 on large samples
Example 1) A newspaper reports that men get married at the age of 25 on average. Researchers think that this claim of the newspaper is not true and the average age of marriage is more than this amount. If in a sample of 213 men who were studied, the average age of marriage is 25.3 and the standard deviation is 2.3, it is desirable to check this claim with a confidence level of 95%.
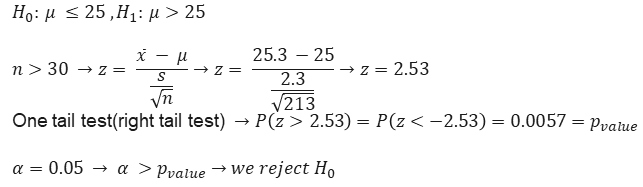
Example 2) An earlier study has shown that families in Tehran have an average of 1.48 children. A researcher claims that this is not the case, he has a sample of 128 with an average of 1.39 and a standard deviation of 0.84. It is desirable to investigate the claim with a confidence level of 90%.

import scipy
print(scipy.__version__)
1.6.2

import pandas as pd
from scipy import stats
df = pd.read_csv('foods.csv')
df.head()
| First Name | Gender | City | Frequency | Item | Spend | |
|---|---|---|---|---|---|---|
| 0 | Wanda | Female | Stamford | Weekly | Burger | 15.66 |
| 1 | Eric | Male | Stamford | Daily | Chalupa | 10.56 |
| 2 | Charles | Male | New York | Never | Sushi | 42.14 |
| 3 | Anna | Female | Philadelphia | Once | Ice Cream | 11.01 |
| 4 | Deborah | Female | Philadelphia | Daily | Chalupa | 23.49 |
q1 : People spend average 60 $$ for food
\[H_0:\mu = 60\] \[H_1:\mu \neq 60\]we use one sample t-test

df.Spend.isna()
0 False
1 False
2 False
3 False
4 False
...
995 False
996 False
997 False
998 False
999 False
Name: Spend, Length: 1000, dtype: bool
df.Spend.isna().sum()
0
alpha = 0.05
tstat,p_value = stats.ttest_1samp(df['Spend'],popmean = 60.0)
print('t stat : {} , p_value : {}'.format(tstat,p_value))
if p_value<= alpha:
print("reject null hypothesis")
else:
print("accept null hypothesis")
t stat : -11.325330284771352 , p_value : 4.645385561029907e-28
t stat : -11.325330284771352 , p_value : 4.645385561029907e-28
reject null hypothesis
q2 : Gender not effects on spending money for food
\[H_1:\mu_{Male} \neq \mu_{Female} \rightarrow \mu_{Male} - \mu_{Female}\neq 0\] \[H_0:\mu_{Male} = \mu_{Female} \rightarrow \mu_{Male} - \mu_{Female} = 0\]because this two group are independent we use 2 sample independent t-test
female = df[df['Gender']== 'Female']
male = df[df['Gender'] == 'Male']
female.head()
| First Name | Gender | City | Frequency | Item | Spend | |
|---|---|---|---|---|---|---|
| 0 | Wanda | Female | Stamford | Weekly | Burger | 15.66 |
| 3 | Anna | Female | Philadelphia | Once | Ice Cream | 11.01 |
| 4 | Deborah | Female | Philadelphia | Daily | Chalupa | 23.49 |
| 11 | Rachel | Female | Philadelphia | Seldom | Sushi | 71.68 |
| 12 | Mary | Female | Philadelphia | Once | Burger | 1.97 |
male.head()
| First Name | Gender | City | Frequency | Item | Spend | |
|---|---|---|---|---|---|---|
| 1 | Eric | Male | Stamford | Daily | Chalupa | 10.56 |
| 2 | Charles | Male | New York | Never | Sushi | 42.14 |
| 5 | Charles | Male | Stamford | Monthly | Sushi | 93.03 |
| 6 | Mark | Male | Philadelphia | Monthly | Ice Cream | 30.01 |
| 7 | Paul | Male | Philadelphia | Monthly | Chalupa | 17.65 |
female.Spend.isna().sum()
0
male.Spend.isna().sum()
0

alpha = 0.05
tstat,p_value = stats.ttest_ind(male.Spend,female.Spend,equal_var = True,alternative='two-sided')
print('t stat : {} , p_value : {}'.format(tstat,p_value))
if p_value<= alpha:
print("reject null hypothesis")
else:
print("accept null hypothesis")
t stat : -0.7477543082151837 , p_value : 0.45478452030140304
accept null hypothesis

q3 : City effects on spending money on food
\[H_0: \mu_{Stamford} = \mu_{New York} = \mu_{Philadelphia}\] \[H_1: \mu_{Stamford} \neq \mu_{New York} \neq \mu_{Philadelphia}\]

df.City.unique()
array(['Stamford', 'New York', 'Philadelphia'], dtype=object)
Stamford = df[df.City=='Stamford']
NewYork = df[df.City=='New York']
Philadelphia = df[df.City == 'Philadelphia']
alpha = 0.05
fstat,p_value = stats.f_oneway(Stamford.Spend ,NewYork.Spend ,Philadelphia.Spend )
print('f stat : {} , p_value : {}'.format(fstat,p_value))
if p_value<= alpha:
print("reject null hypothesis")
else:
print("accept null hypothesis")
f stat : 0.07504725668463724 , p_value : 0.9277048853823887
accept null hypothesis
q4 : relation item as categorical feature and city as categorical feature
contingency_table=pd.crosstab(df["City"],df["Item"])
print('contingency_table : \n',contingency_table)
contingency_table :
Item Burger Burrito Chalupa Donut Ice Cream Sushi
City
New York 46 48 44 61 56 58
Philadelphia 52 58 55 63 73 58
Stamford 58 62 48 63 47 50
contingency_table.values
array([[46, 48, 44, 61, 56, 58],
[52, 58, 55, 63, 73, 58],
[58, 62, 48, 63, 47, 50]])
chi2_stat , p_value , dof , expected = stats.chi2_contingency(contingency_table.values)
print('dof : ',dof)
dof : 10
print('chi2 stat : {} , p_value : {}'.format(chi2_stat,p_value))
chi2 stat : 7.942425445331459 , p_value : 0.6344608189675968
print('expected value : \n',expected)
expected value :
[[48.828 52.584 46.011 58.531 55.088 51.958]
[56.004 60.312 52.773 67.133 63.184 59.594]
[51.168 55.104 48.216 61.336 57.728 54.448]]
alpha = 0.05
if p_value<=alpha:
print("Reject H0,There is a relationship between 2 categorical variables")
else:
print("Retain H0,There is no relationship between 2 categorical variables")
Retain H0,There is no relationship between 2 categorical variables
q5 : new drug can reduce blood pressure level
\[H_0 : \mu_{before} = \mu_{after}\] \[H_1 : \mu_{before} \neq \mu_{after}\]we have 2 dependent sample , we use 2 sample dependent test
df = pd.read_csv(root + 'blood_pressure.csv')
df.head()
| patient | sex | agegrp | bp_before | bp_after | |
|---|---|---|---|---|---|
| 0 | 1 | Male | 30-45 | 143 | 153 |
| 1 | 2 | Male | 30-45 | 163 | 170 |
| 2 | 3 | Male | 30-45 | 153 | 168 |
| 3 | 4 | Male | 30-45 | 153 | 142 |
| 4 | 5 | Male | 30-45 | 146 | 141 |

alpha = 0.05
tstat,p_value = stats.ttest_rel(df['bp_before'],df['bp_after'],alternative='two-sided')
print('t stat : {} , p_value : {}'.format(tstat,p_value))
if p_value<= alpha:
print("reject null hypothesis")
else:
print("accept null hypothesis")
t stat : 3.3371870510833657 , p_value : 0.0011297914644840823
reject null hypothesis