Merging, Joining and Concatenating DataFrames
Adding / Concatenating Rows (Part 1)
import pandas as pd
men2004 = pd.read_csv("men2004.csv")
men2004
| Athlete | Medals | |
|---|---|---|
| 0 | PHELPS, Michael | 8 |
| 1 | THORPE, Ian | 4 |
| 2 | SCHOEMAN, Roland | 3 |
| 3 | PEIRSOL, Aaron | 3 |
| 4 | CROCKER, Ian | 3 |
| 5 | KITAJIMA, Kosuke | 3 |
| 6 | HANSEN, Brendan | 3 |
| 7 | VAN DEN HOOGENBAND, Pieter | 3 |
| 8 | HACKETT, Grant | 3 |
| 9 | MORITA, Tomomi | 2 |
| 10 | LEZAK, Jason | 2 |
| 11 | ROGAN, Markus | 2 |
| 12 | KELLER, Klete | 2 |
| 13 | HALL, Gary Jr. | 2 |
| 14 | LOCHTE, Ryan | 2 |
| 15 | WALKER, Neil | 2 |
| 16 | YAMAMOTO, Takashi | 2 |
| 17 | SPRENGER, Nicholas | 1 |
| 18 | OKUMURA, Yoshihiro | 1 |
| 19 | PARRY, Stephen | 1 |
| 20 | PEARSON, Todd | 1 |
| 21 | ZASTROW, Mitja | 1 |
| 22 | PELLICIARI, Matteo | 1 |
| 23 | WOODWARD, Gabe | 1 |
| 24 | SERDINOV, Andriy | 1 |
| 25 | VENDT, Erik | 1 |
| 26 | ROSOLINO, Massimiliano | 1 |
| 27 | VEENS, Mark Hermanus | 1 |
| 28 | RUPPRATH, Thomas | 1 |
| 29 | VANDERKAAY, Peter | 1 |
| 30 | TOWNSEND, Darian | 1 |
| 31 | STEVENS, Craig | 1 |
| 32 | NEETHLING, Ryk | 1 |
| 33 | BOVELL, George | 1 |
| 34 | MEEUW, Helge | 1 |
| 35 | FLOREA, Razvan Ionut | 1 |
| 36 | CAPPELLAZZO, Federico | 1 |
| 37 | CERCATO, Simone | 1 |
| 38 | CONRAD, Lars | 1 |
| 39 | CSEH, Laszlo | 1 |
| 40 | DAVIES, David | 1 |
| 41 | DRAGANJA, Duje | 1 |
| 42 | DRIESEN, Steffen | 1 |
| 43 | DUBOSCQ, Hugues | 1 |
| 44 | DUSING, Nate | 1 |
| 45 | FERNS, Lyndon | 1 |
| 46 | GANGLOFF, Mark | 1 |
| 47 | MATKOVICH, Antony | 1 |
| 48 | GOLDBLATT, Scott | 1 |
| 49 | GYURTA, Daniel | 1 |
| 50 | JENSEN, Larsen | 1 |
| 51 | KENKHUIS, Johan | 1 |
| 52 | KETCHUM, Dan | 1 |
| 53 | KLIM, Michael | 1 |
| 54 | KRAYZELBURG, Lenny | 1 |
| 55 | KRUPPA, Jens | 1 |
| 56 | BREMBILLA, Emiliano | 1 |
| 57 | MAGNINI, Filippo | 1 |
| 58 | ZWERING, Klaas-Erik | 1 |
men2008 = pd.read_csv("men2008.csv")
men2008
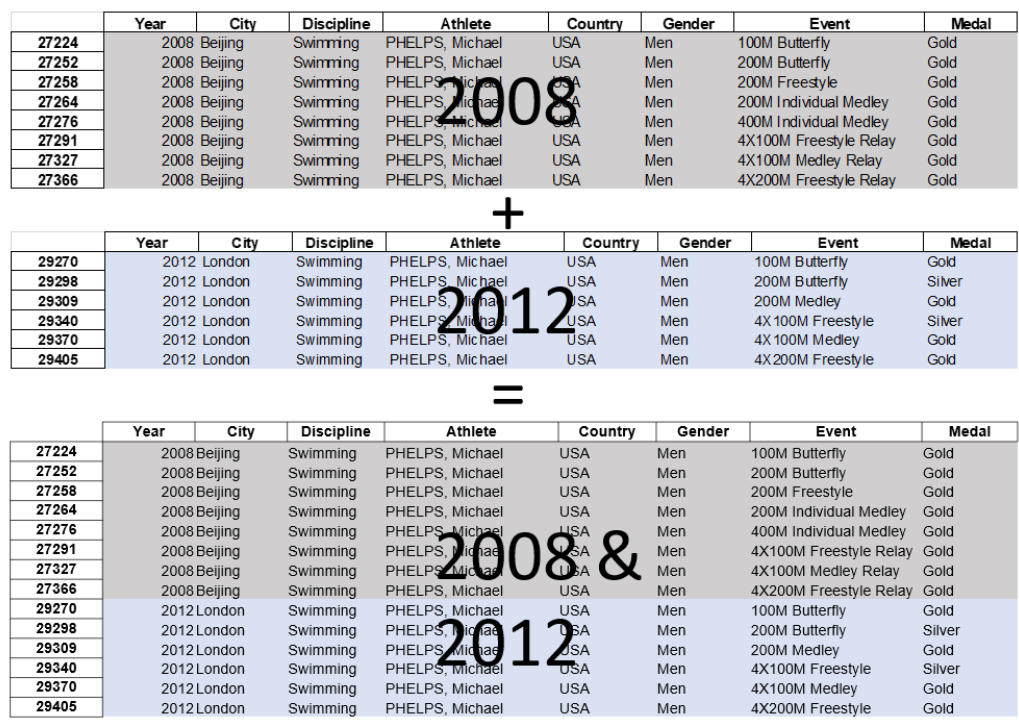
men2004.append(men2008, ignore_index= True)
men0408 = pd.concat([men2004, men2008], ignore_index=False, keys = [2004, 2008], names = ["Year"])
men0408
men0408.reset_index().drop(columns = "level_1")
Adding / Concatenating Rows (Part 2)
men2004.head()
men2008.head()
men2004.columns =["Name", "Medals"]
men2004["Success"] = "Yes"
men2004
pd.concat([men2004, men2008], keys = [2004, 2008], names = ["Year"])
men2004.drop(labels = ["Success"], axis = 1, inplace = True)
men2004
men2008.columns = men2004.columns
men2008.head()
pd.concat([men2004, men2008], keys = [2004, 2008], names = ["Year"])
men2004 = pd.read_csv("men2004.csv", index_col = "Athlete")
men2008 = pd.read_csv("men2008.csv", index_col = "Athlete")
men2004.head()
men2008.head()
pd.concat([men2004, men2008], ignore_index= False, keys = [2004, 2008])
Arithmetic between Pandas Objects / Data Alignment
import pandas as pd
topfive_2004 = pd.read_csv("topfive_2004.csv", index_col="Athlete")
topfive_2008 = pd.read_csv("topfive_2008.csv", index_col="Athlete")
topfive_2004
topfive_2008
topfive_2004 + topfive_2008
topfive_2004.add(topfive_2008, fill_value= 0)
topfive_2008.rename(columns = {"bronze":"Bronze"}, inplace = True)
topfive_2004.add(topfive_2008, fill_value= 0)
topfive_2004.sub(topfive_2008, fill_value= 0)
Outer Join
import pandas as pd
men2004 = pd.read_csv("men2004.csv")
men2008 = pd.read_csv("men2008.csv")
men2004.head()
men2004.shape
men2008.head()
men2008.shape
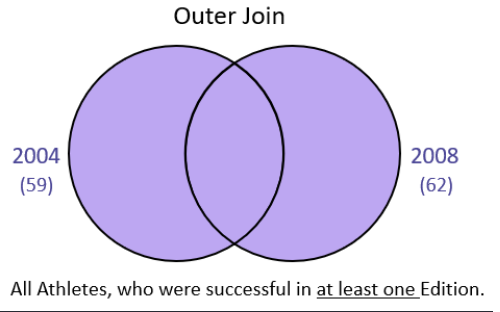
len(men2008) + len(men2004)
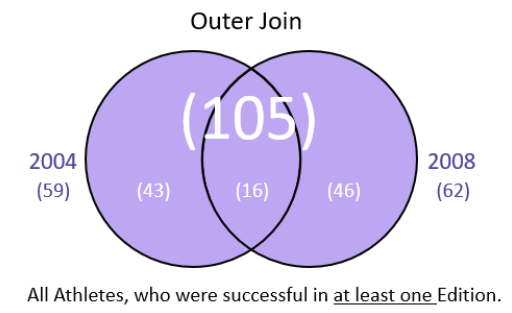
men2004.merge(men2008, how = "outer", on = "Athlete", suffixes= ("_2004", "_2008"), indicator= True )
men0408 = men2004.merge(men2008, how = "outer", on = "Athlete", suffixes= ("_2004", "_2008"), indicator= True )
men0408._merge.value_counts()
Inner Join
men2004.head()
men2008.head()
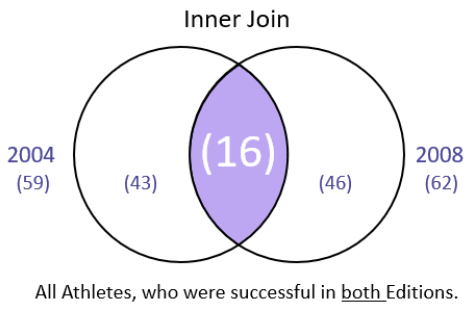
men2004.merge(men2008, how = "inner", on = "Athlete", suffixes= ("_2004", "_2008"), indicator= True )
Outer Join without Intersection
men2004.head()
men2008.head()
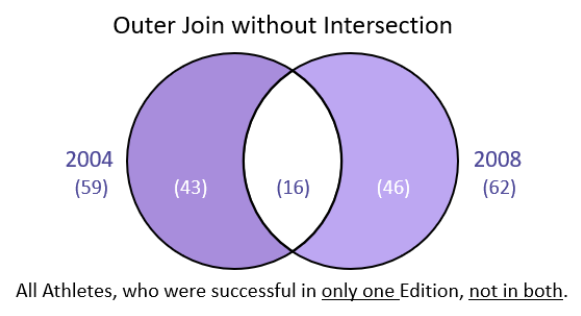
men0408= men2004.merge(men2008, how = "outer", on = "Athlete", suffixes= ("_2004", "_2008"), indicator= True )
men0408.loc[men0408._merge != "both"]
Left Join without Intersection
men2004.head()
men2008.head()
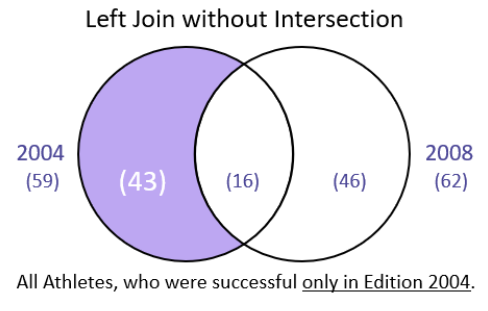
men0408 = men2004.merge(men2008, how = "outer", on = "Athlete", suffixes= ("_2004", "_2008"), indicator= True )
men0408.head()
men0408[men0408._merge == "left_only"].shape
Right Join without Intersection
men2004.head()
men2008.head()
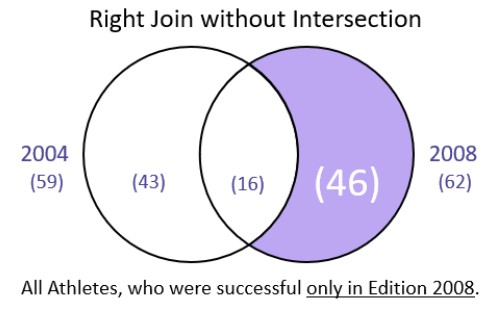
men0408 = men2004.merge(men2008, how = "outer", on = "Athlete", suffixes = ["_2004", "_2008"], indicator = True)
men0408[men0408._merge == "right_only"].shape
Left Join
men2004.head()
men2008.head()
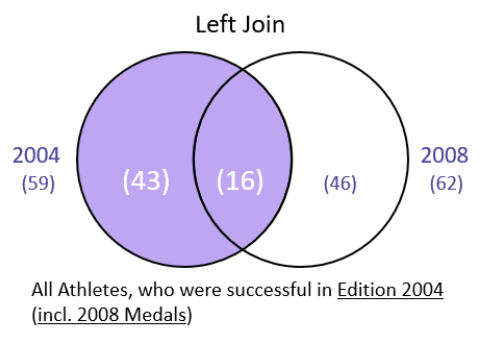
men2004.merge(men2008, how = "left", on = "Athlete", suffixes = ["_2004", "_2008"], indicator = True)
Right Join
men2004.head()
men2008.head()
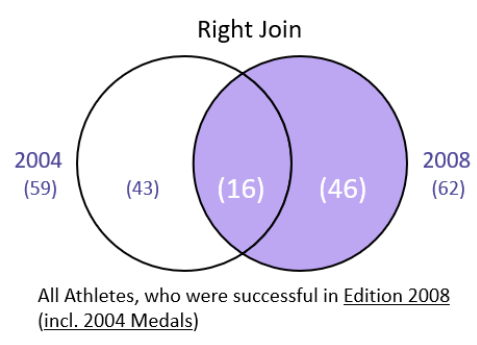
men2004.merge(men2008, how = "right", on = "Athlete", suffixes = ["_2004", "_2008"], indicator = True)
Joining on different Column Labels & Indexes
import pandas as pd
men2004 = pd.read_csv("men2004.csv")
men2008 = pd.read_csv("men2008.csv")
men2004.head()
| Name | Medals | |
|---|---|---|
| 0 | PHELPS, Michael | 8 |
| 1 | THORPE, Ian | 4 |
| 2 | SCHOEMAN, Roland | 3 |
| 3 | PEIRSOL, Aaron | 3 |
| 4 | CROCKER, Ian | 3 |
men2008.head()
| Athlete | Medals | |
|---|---|---|
| 0 | PHELPS, Michael | 8 |
| 1 | LOCHTE, Ryan | 4 |
| 2 | BERNARD, Alain | 3 |
| 3 | SULLIVAN, Eamon | 3 |
| 4 | LAUTERSTEIN, Andrew | 3 |
men2004.columns = ["Name", "Medals"]
men2004.head()
| Name | Medals | |
|---|---|---|
| 0 | PHELPS, Michael | 8 |
| 1 | THORPE, Ian | 4 |
| 2 | SCHOEMAN, Roland | 3 |
| 3 | PEIRSOL, Aaron | 3 |
| 4 | CROCKER, Ian | 3 |
men0408 = men2004.merge(men2008, how = "outer", left_on = "Name", right_on = "Athlete",
suffixes = ["_2004", "_2008"], indicator = True)
men0408
| Name | Medals_2004 | Medals_2008 | |
|---|---|---|---|
| 0 | PHELPS, Michael | 8.0 | 8.0 |
| 1 | THORPE, Ian | 4.0 | NaN |
| 2 | SCHOEMAN, Roland | 3.0 | NaN |
| 3 | PEIRSOL, Aaron | 3.0 | 3.0 |
| 4 | CROCKER, Ian | 3.0 | 1.0 |
| ... | ... | ... | ... |
| 100 | LAGUNOV, Evgeniy | NaN | 1.0 |
| 101 | BERENS, Ricky | NaN | 1.0 |
| 102 | LURZ, Thomas | NaN | 1.0 |
| 103 | MALLET, Gregory | NaN | 1.0 |
| 104 | ZHANG, Lin | NaN | 1.0 |
105 rows × 3 columns
men0408.Name.fillna(men0408.Athlete, inplace = True)
men0408.drop(["Athlete", "_merge"], axis = 1, inplace = True)
men2004.head()
| Name | Medals | |
|---|---|---|
| 0 | PHELPS, Michael | 8 |
| 1 | THORPE, Ian | 4 |
| 2 | SCHOEMAN, Roland | 3 |
| 3 | PEIRSOL, Aaron | 3 |
| 4 | CROCKER, Ian | 3 |
men2008.set_index("Athlete", inplace = True)
men2008.head()
men2004.merge(men2008, how = "outer", left_on= "Name", right_index = True,
suffixes = ["_2004", "_2008"], indicator = True)
| Name | Medals_2004 | Medals_2008 | _merge | |
|---|---|---|---|---|
| 0.0 | PHELPS, Michael | 8.0 | 8.0 | both |
| 1.0 | THORPE, Ian | 4.0 | NaN | left_only |
| 2.0 | SCHOEMAN, Roland | 3.0 | NaN | left_only |
| 3.0 | PEIRSOL, Aaron | 3.0 | 3.0 | both |
| 4.0 | CROCKER, Ian | 3.0 | 1.0 | both |
| ... | ... | ... | ... | ... |
| NaN | LAGUNOV, Evgeniy | NaN | 1.0 | right_only |
| NaN | BERENS, Ricky | NaN | 1.0 | right_only |
| NaN | LURZ, Thomas | NaN | 1.0 | right_only |
| NaN | MALLET, Gregory | NaN | 1.0 | right_only |
| NaN | ZHANG, Lin | NaN | 1.0 | right_only |
105 rows × 4 columns
Joining on many Columns
import pandas as pd
men2004_det = pd.read_csv("men2004_det.csv")
men2008_det = pd.read_csv("men2008_det.csv")
men2004_det.head(10)
men2008_det.head(10)
men2004_det.loc[men2004_det.Athlete == "PHELPS, Michael"]
men2008_det.loc[men2008_det.Athlete == "PHELPS, Michael"]
men0408 = men2004_det.merge(men2008_det, how = "inner", on = ["Athlete", "Medal"], suffixes= ("_2004", "_2008"))
men0408.loc[men0408.Athlete == "PHELPS, Michael"]
pd.merge and join()
import pandas as pd
men2004 = pd.read_csv("men2004.csv", index_col = "Athlete")
men2008 = pd.read_csv("men2008.csv", index_col = "Athlete")
men2004.head()
men2008.head()
men2004.merge(men2008, how = "outer", on = "Athlete", suffixes= ("_2004", "_2008"), indicator= True)
pd.merge(men2004, men2008, how ="outer", on = "Athlete", suffixes= ("_2004", "_2008"), indicator= True )
men2004.join(men2008, how = "outer", lsuffix = "_2004", rsuffix = "_2008")